





























Artificial Intelligence has been revolutionizing all industries and simultaneously reshaping the way we have been perceiving the world. From document summarization to self-driving cars, AI has become a driving force in nearly every aspect of our lives. There are those who argue that AI has indeed taken over humanity, and regrettably, they may not be entirely wrong. However, it is essential to clarify that this takeover does not manifest as dystopian robots ruling the planet, obviously, that would be a nightmare! Rather, it is evident in the automation of countless small tasks that previously required human intervention. This rapid progress is fueled by the abundance of data available, providing the foundation for intelligent AI systems to learn and evolve. Learn how to easily build AI–powered web applications in this blog post with details.
But one thing is evident, as software developers, we find ourselves at the forefront of this AI-driven revolution, benefiting from the creation of innovative ventures and business opportunities. In this article, we will dive into various areas of AI, including Machine Learning, Deep Learning, and Generative AI. Our focus will be on leveraging state-of-the-art models to build AI-powered web applications. Whether you aspire to establish your own SaaS (Software as a Service) startup or simply want to expedite app development without going into unnecessary details about how AI models work, this article will serve as a Kickstarter for your journey.
Now, Let’s dive into the 6-step process:
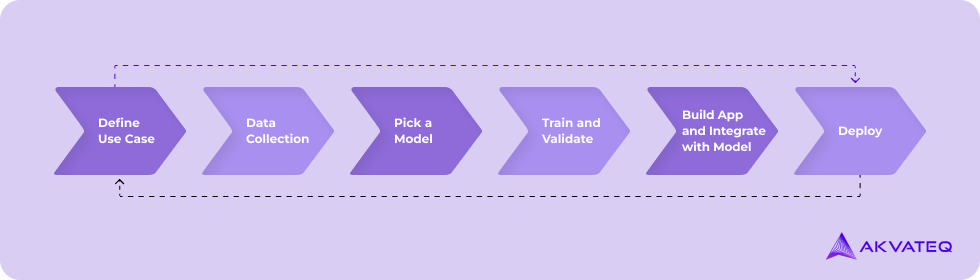
To keep things simple, I have divided the entire process into the following phases, we will be combining a typical machine learning model development life-cycle and software development life-cycle together since the outcome we are aiming for is a fully functional AI-powered web application. This approach ensures that you address both the technical aspects of model development plus the user experience and functionality of the web application.
Note: The steps mentioned here can vary depending on the use case of your application and the given scenario, for instance, you might find many pre-trained AI models that can directly be consumed by using their inference guidelines, so you can simply skip the training and validation step, similarly many AI services even offer simple APIs for model inference, so you can further skip the backend development and model integration steps and jump directly to Client-side application development phase.
get in touch to discuss your project
Step 1: Define the Use case
So we begin our journey here, the first and foremost step is to clearly define the problem you aim to solve with your AI-powered web Application, this will involve defining the end-to-end flow of your application and identifying the specific tasks or challenges you want the app to address. This will serve as the foundation for the development process, you can start with the following checklist:
- Find your motivation: Clearly define the specific problem or challenge that the web app should address. The pain points or inefficiencies that users may encounter and determine how your web app can fix them.
- Do you even need AI ?: Evaluate whether AI technology is appropriate for solving the identified problem. Determine if there exists a simpler mathematical/statistical approach that can be used to solve the problem.
- Look for existing solutions: Analyze the market to identify existing solutions or competitors. Determine your Unique Selling Point (USP) to stand out in the market.
- Do you have enough data ?: Probably the most important question, assess the availability and quality of data required for training and deploying AI models, the accuracy and performance of your AI app will heavily rely on the data you will be using for training your AI model which is our fourth step.
Step 2: Data Collection
Gather the relevant data needed to train and validate your AI models. Although I have been emphasizing the quantity of data contrary to that, the data should preferably be of high quality, and diversity and should represent the problem domain, a typical flow of collecting data for all types of AI models might include the following steps:
- Finding data sources: Data can be either structured such as databases, CSVs, or annotated images, or it can be unstructured such as data available on websites, and social media posts for which you might consider building web crawlers or scrappers to extract this data in compliance with the privacy regulations and ethical considerations.
- Labeling or Annotating Data: Depending on your use case, you may need to label or annotate the collected data to provide correct information for training the AI models. This might involve manually assigning labels or using tools to annotate images, texts, or other types of data.
- Data Cleaning and Pre-processing: Data collected from various sources may contain noise, missing values, or inconsistencies. Perform data cleaning and pre-processing tasks such as removing duplicates, handling missing data, standardizing formats, and normalizing values. This ensures that the data is in a suitable format for training and analysis.
- Storing and Retrieving Data: Set up a robust and secure data storage system to store the collected and processed data. This can involve using databases, cloud storage solutions, or other data management platforms. Consider organizing the data in a structured manner to facilitate easy retrieval and analysis.
- Updating Datasets Continuously: In certain cases, it is important to keep the dataset up to date to ensure the AI models remain accurate and effective. You might need to Implement mechanisms to continuously collect new data, you can build automated processes to retrain your model. on the most recent and relevant information.
get in touch to discuss your project
Step 3: Pick your Model
Choosing the appropriate AI model or combination of models that best align with your use case is the third step, this phase can be time-consuming as you need to carefully consider factors such as the type of data your model can process, the complexity of the problem, and the available computational resources. Here you might need to even train your own models from scratch using popular frameworks like TensorFlow or PyTorch, this is only needed if you have to collect data in step two for a specific use case.
Artificial Intelligence applications generally fall into three categories: traditional machine learning models, advanced deep learning/neural network models, and generative models as depicted in the Venn diagram below. Each category corresponds to specific areas of expertise within the field of Artificial Intelligence. Noteworthy advancements in these areas have led to significant progress and breakthroughs in AI technology.
It is essential to carefully assess the requirements of your use case and select the most suitable model(s) accordingly. This process may involve experimentation and evaluation to determine the best model that aligns with your specific needs.
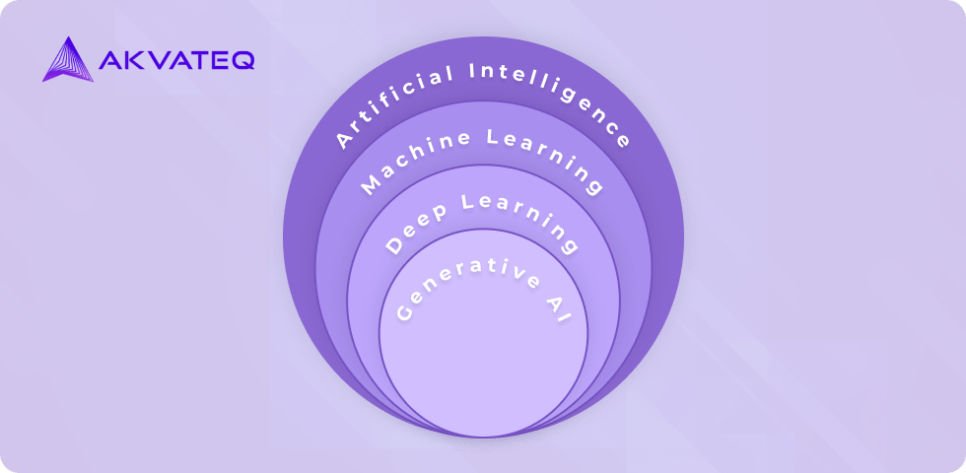
As a rule of thumb, we can categorize and select models based on the types of data they process and the corresponding output they generate. By adopting this top-down approach, we can recognize that each model excels at a specific task.
Here’s an example: Let’s assume you are building an application that removes plagiarism from a provided document, the type of model you are looking for must process lengthy text and should generate a plagiarism-free version of that text, by narrowing down our search, we can focus on text-based models like Transformers (such as GPT-3 or BERT), which excel at generating textual content.
In general, we can classify the models in the following format:
- Models for Text Processing
- Models for Image Processing
- Models for Audio Processing
Models for Text Processing
When developing a web application for natural language processing, it is crucial to choose models that excel in analyzing textual data. However, it is important to note that while advanced models like Transformers can easily handle tasks such as text classification or summarization, they may not be the most cost-effective and computationally efficient solution for such small tasks. Therefore, selecting the appropriate model tailored to your specific requirement becomes crucial.
- Word2Vec: Word2Vec is a popular word embedding model that represents words as dense vectors, capturing their semantic relationships. It is useful for tasks such as text similarity, and text classification.
- Recurrent Neural Networks (RNN): RNNs are designed to process sequential data and have a memory to retain information from previous inputs. They are widely used for tasks like language modeling, text generation, sentiment analysis, and machine translation.
- Long Short-Term Memory (LSTM): LSTM is a specialized RNN architecture with improved memory capabilities, making it suitable for tasks involving long-term dependencies, such as sentiment analysis, named entity recognition, and text summarization these models can be ideal for applications like detecting
- Convolutional Neural Networks (CNN): CNNs although commonly have their applications in image processing, can also be applied to text data by converting text into a form that is required by these models. They can be effective in tasks like text classification, sentiment analysis, and named entity recognition.
- Transformers: Transformers have gained significant attention for their ability to capture global relationships in the text through self-attention mechanisms. They excel in tasks such as machine translation, language generation, text summarization, and question-answering systems, these models are part of Generative AI models, architecture Natural language processing techniques, and. Some popular and widely used large language models that are extended versions of these transformers are BERT, GPT-3, GPT-4, and PaLM, which are part of popular applications like OpenAI’s ChatGPT and Google’s Bard.
- GPT (Generative Pre-trained Transformer): Although I already mentioned GPT-3 with transformers, GPT models have some significant amount of additional applications, these are large-scale language models that generate coherent and contextually relevant text. They even excel in tasks like text generation, and text completion.

Models for Image Processing
Image processing is a crucial aspect of computer vision and involves a wide range of techniques and models to analyze and extract meaningful information from images. It’s important to choose the right model based on the specific task at hand, as using advanced models for simple image processing tasks might not be the most efficient and cost-effective solution in terms of computational resources.
- Traditional Image Processing Models: Models such as Haar Cascade classifiers can prove to be a simple and efficient solution for tasks like face detection, pedestrian detection, and basic object recognition and can be implemented with a library like OpenCV which provides all such classifiers as built-in modules.
- Convolutional Neural Networks (CNN): CNNs are also good at processing visual data. Almost all popular models use CNNs as their foundation They are widely used for image classification, object detection, image segmentation, and content-based image retrieval. Some popular and widely used CNNs for the mentioned applications are AlexNet, VGGNet, MobileNet, and GoogleNet, etc).
- Faster R-CNN: Faster R-CNN is an advanced object detection model that combines region proposal networks with CNNs. It is used for accurate and efficient object detection and localization in images (Some popular models include YOLO and SSD).
- Mask R-CNN: Mask R-CNN is based on Faster R-CNN, it further provides pixel-level object segmentation in addition to object detection. It is useful for tasks like instance segmentation which is mostly used in applications like Background removal from detected objects.
- Generative Adversarial Networks (GAN): These are powerful models for generating realistic images. They are used in applications like image synthesis, style transfer, and data augmentation, Some popular applications of these models are MidJourney and OpenAI’s DALLE-2
Models for Audio Processing
Audio processing may appear simpler at first glance, as one might assume that speech-to-text approaches can be used to convert spoken language into text, followed by applying text processing models for analysis. However, the challenge lies in the fact that audio data can take various forms, including animal sounds, car honks, and more. This diversity requires specialized techniques for accurate classification, here are a few popular models for processing audio based on their applications.
- Audio Classification: Some popular and widely used models for audio classification are VGGish which is a deep neural network model for audio classification, and MobileNetV1 which is another lightweight model suitable for audio classification on resource-constrained devices.
- Speech to Text: These types of tasks involve converting audio input into textual data and there are some popular models available for this purpose such as Wav2Vec and Speech processing engines such as DeepSpeech and OpenAI’s Whisper they provide automatic speech recognition (ASR) for applications like voice assistants and transcription of videos.
- Audio Segmentation: For audio segmentation tasks, models like Wave-U-Net, and CRNN (Convolutional Recurrent Neural Network) are commonly used. These models can analyze audio signals and segment them into meaningful components, such as identifying different speakers in a conversation or separating music from background noise.
- Audio Generation: These types of tasks often involve generating new audio from existing data, it is now possible with the rise of Generative AI, that models such as WaveGAN and SampleRNN can do tasks like audio synthesis.
get in touch to discuss your project
Step 4: Training your model
Okay, so you have selected a model, which is great! But there’s just one more essential step left. Now, you need to feed this model with data. However, if you are lucky enough to have found a pre-trained model that yields the exact results during inference, you can skip this phase
Some of the biggest challenges in this phase include the availability of a training dataset and the computational resources required to speed up the training process. As a developer, you might not have anticipated these challenges. However, there’s no need to worry. We still have options available. If you were lucky enough to have a powerful GPU with CUDA cores, that’s great. But for most developers, here are four alternatives for expediting your training process:
- Transfer Learning: Transfer learning involves leveraging pre-trained models that have been trained on large datasets. Instead of training a model from scratch, you can use a pre-trained model as a starting point and fine-tune it on your specific task or dataset, A few popular examples include Google’s Teachable Machine and Tensorflow Hub.
- Online Platforms and APIs: Many online platforms and APIs provide user-friendly interfaces and tools for training AI models. These platforms allow you to upload your data and train custom models without requiring extensive knowledge of machine learning algorithms or programming, Some popular platforms include Google Cloud AutoML, IBM Watson, and Microsoft Azure Machine Learning.
- High-Level Libraries and Frameworks: While this is not going to save your training time utilizing high-level libraries and frameworks can speed up your model development time. TensorFlow, PyTorch, and Keras provide easy-to-use APIs and abstractions that handle many of the underlying complexities of model training.
- Cloud Computing: Cloud computing platforms, such as Amazon Web Services (AWS), Google Cloud Platform (GCP), and Microsoft Azure, provide powerful infrastructure, scalable computing resources, specialized hardware like GPUs and TPUs, and even pre-configured environments for machine learning.
Step 5: Build your application
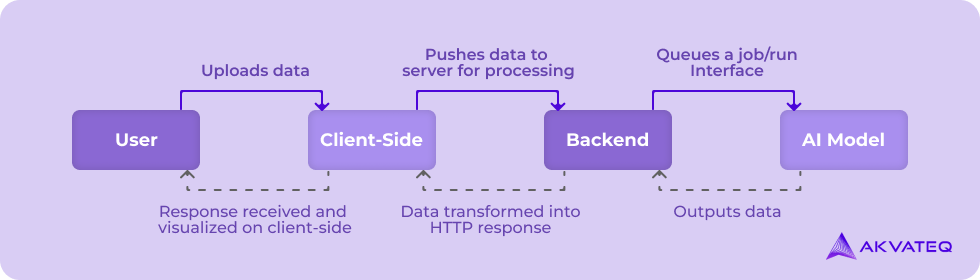
Now we have our model ready for inference, we can start designing and building AI-powered web applications and overall infrastructure to integrate the AI model. Here’s a generic architecture most of the AI-powered web apps would use, it will be a full stack application with an additional component integrated with the back-end for processing, you need to figure out how the client-side application will dispatch jobs up to this module, let’s break it down:
- Build User Interface: Building an intuitive front-end for your app is important, the first step is to figure out what type of data the user will be uploading, and depending on the size of this data, you might need to queue jobs for processing this data from multiple users, client-side must indicate the progress of this job to every user since the core part of the entire application is the AI model, we need to keep the user interface as simple and minimal as possible.
- Build back-end: The back-end serves as the broker between the client-side and AI model, responsible for processing the data uploaded by the user as it traverses through the pipeline. The back-end server ensures that the data is pre-processed appropriately before being fed into the AI model. Similarly, the output generated by the AI model needs to be parsed and converted into a suitable format that can be visualized on the client side.
- Bridge AI model with application: This last step is to build a communication mechanism between the backend of your app and the AI model, this is where you need to figure out, how you will execute your model weight files for inference since these files get executed from command line and might require the availability of a python interpreter and libraries like PyTorch or Tensorflow, what this simply implies is that your AI model can be considered an entirely separate process and will function as an independent component while providing the desired output, To simplify the deployment and integration of your AI model, you have several options.
One approach is to deploy the model on a cloud platform, where you can take advantage of the platform’s infrastructure and services to execute and manage the model. Another option is to create a separate microservice dedicated to executing the AI model. This microservice can be designed to receive requests from the backend, process them using the AI model, and return the results. Additionally, you can consider containerizing your model using technologies like Docker or Kubernetes. Containerization will allow you to encapsulate the AI model along with its dependencies into a self-contained unit that can be easily deployed and managed.
Step 6: Deployment
It’s time to finally get your application out there, this is where you need to deploy your web app to a hosting platform or server, since each component of our app was built independently, it can also be deployed independently. Ensure that the necessary infrastructure and dependencies are in place to support the app’s performance and scalability.
Well! If you have deployed your AI model on a cloud platform that offers elastic services for auto-scaling, you’re all good, as now you can benefit from automatic scaling as the number of users and processing jobs increase. This ensures that your app can handle the growing demand without compromising performance.
For the backend of your web app, consider implementing scalability measures as the number of users and processing requirements grow. This may involve scaling up your server resources or utilizing load-balancing techniques to distribute the workload effectively.
If you are looking for dedicated PHP developers to hire, we can help you!
Conclusion
In conclusion, embarking on the journey of building AI–powered web applications for the future is both fun and promising. By following these six steps diligently, you can navigate this process with clarity and confidence, ensuring a successful outcome.
In today’s fast-paced world, AI has emerged as a formidable force, offering an abundance of tools and frameworks that have made the development of AI-powered web apps more accessible than ever before. The power of AI lies in its ability to analyze vast amounts of data, discover hidden patterns, and make intelligent predictions. By integrating AI capabilities into web apps, you can enhance user experiences, streamline processes, and deliver unparalleled value to your users.
get in touch to discuss your project

Syed Ali Rizvi
Senior Software Engineer at Akvateq